
成都中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2023-01-03 来源:黑马程序员 浏览量:

Excel文件是比较常见的用于存储数据的方式,它里面的数据均是以二维表格的形式显示的,可以对数据进行统计、分析等操作。Excel的文件扩展名有.xls和.xlsx两种。
Pandas中提供了对Excel文件进行读写操作的方法,分别为to_excel()方法和read_excel()函数,关于它们的具体操作如下。
to_excel()方法的功能是将DataFrame对象写入到Excel工作表中,该方法的语法格式如下:
to_excel(excel_writer,sheet_name='Sheet',na_rep='', float_format+None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None)
上述方法中常用参数表示的含义如下:
(1)excel_writer:表示读取的文件路径。
(2)sheet_name:表示工作表的名称,可以接收字符串,默认为“Sheet1”。
(3)na_rep:表示缺失数据。
(4)index:表示是否写行索引,默认为True。
为了能够让大家更好地理解,接下来,创建一个2行2列的DataFrame对象,之后将该对象写入到itcast.xlsx文件中,具体代码如下。
In [83]: import pandas as pd
df1 = pd.DataFrame({'col': ['传', '智'], 'col2': ['播', '客']})
df1.to_excel(r'E:\数据分析\itcast.xlsx','python基础班')
'写入完毕'
Out[83]:'写入完毕' 打开“E:\数据分析”目录下的itcast.xlsx文件,文件的内容如图3-12所示。
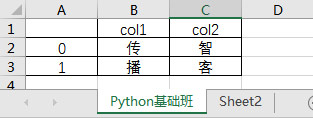
图3-12 打开itcast.xlsx文件
值得一提的是,如果写入的文件不存在,则系统会自动创建一个文件,反之则会将原文中的内容进行覆盖。





















.jpg)