
成都中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2022-10-07 来源:黑马程序员 浏览量:

在Pandas中,大多数据是以便于操作的DataFrame形式展现的,这样可以很容易地获取每行或每列的数据。不过有些时候,需要将DataFrame对象转换为Series对象。为此,Pandas提供了数据重塑的一些功能,包括重塑层次化索引和轴向转换,用于转换一个表格或向量的结构,使其更便于进行下一步的分析。接下来,笔者先来介绍一下数据重塑的相关功能进行详细地介绍。
Pandas中重塑层次化索引的操作主要是stack()方法和unstack()方法,前者是将数据的列“旋转”为行,后者是将数据的行“旋转”为列。
stack()方法可以将数据的列索引转换为行索引,其语法格式如下:
DataFrame.stack(level=-1, dropna=True)
上述方法中部分参数表示的含义如下:
(1)level:表示操作内层索引。若设为0,表示操作外层索引,默认为-1。
(2)dropna:表示是否将旋转后的缺失值删除,若设为True,则表示自动过滤缺失值,设置为False则相反。
假设现在有一个DataFrame类对象df,它只有单层索引,如果希望将其重塑为一个具
有两层索引结构的对象result,也就是说将列索引转换成内层行索引,则重塑前后的效果如图4-22所示。
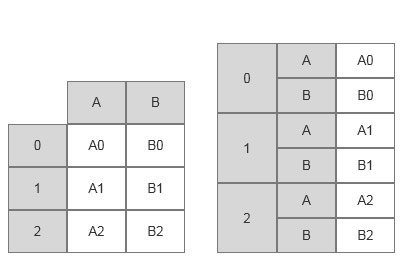
图4-22 DataFrame对象重塑为Series对象
接下来,我们通过一个示例来演示如何使用stack()方法将df对象转换成result,具体代码如下:
In [33]: import pandas as pd
df=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2']}
# 将df进行重塑
result=df.stack()
result
Out[33]:
0 A A0
B B0
1 A A1
B B1
2 A A2
B B2上述代码中,首先创建了一个DataFrame类的对象df,然后让df对象调用stack()方法进行重塑,表明df对象的列索引会转换成行索引。从输出结果看出,result对象具有两层行索引。
使用type()函数来查看result的类型,代码如下:
In [34]: type(result) Out[34]: pandas.core.series.Series
从输出结果可以看出,DataFrame对象已经被转换成一个Series对象。
unstack()方法可以将数据的行索引转换为列索引,其语法格式如下:
DataFrame.unstack(level=-1, fill_value=None)
上述方法中部分参数表示的含义如下:
(1)level:默认为-1,表示操作内层索引,0表示操作外层索引。
(2)fill_value:若产生了缺失值,则可以设置这个参数用来替换NaN。
接下来,将前面示例中重塑的Series对象“恢复原样”,转变成DataFrame对象,具体代码如下:
In [35]: import pandas as pd
df=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2']}
res=df.stack() # 将df重塑为Series对象
res.unstack() # 将Series对象转换成df
Out[35]:
A B
0 A0 B0
1 A1 B1
2 A2 B2上述示例中,首先创建了一个DataFrame类对象df,然后使用stack()方法将其重塑为Series类对象,最后再使用unstack()方法将其重塑回DataFrame类对象。




















.jpg)