



Python模块的开头通常会定义一个__all__属性,该属性实际上是一个元组,该元组中包含的元素决定了在使用from…import 语句导入模块内容时通配符所包含的内容。 如果__all__中只包含模块的部分内容,那么from…import *语句只会将__all__中包含的部分内容导入程序。查看全文>>

break语句用于跳出离它最近一级的循环,能够用于for循环和while循环中,通常与if语句结合使用,放在if语句代码块中,其格式如下所示。查看全文>>
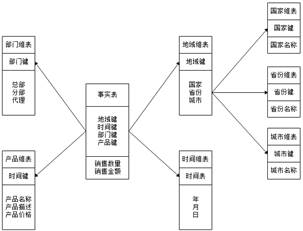
在数据仓库建设中,一般会围绕着星型模型和雪花模型来设计数据模型。下面就来介绍一下这两种数据模型。查看全文>>

Scrapy的运作流程由引擎控制,其过程如下:(1)引擎向Spiders请求第个要爬取的URL(s)。(2)引擎从Spiders中获取到第一个要爬取的URL,封装成Request并交给调度器。(3)引擎向调度器请求下一个要爬取的Request。查看全文>>

根据使用场景,网络爬虫可分为通用爬虫和聚焦爬虫两种。通用爬虫是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。聚焦爬虫,是“面向特定主题需求”的一种网络爬虫程序。接下来,就对这两种爬虫分别进行介绍。查看全文>>

NumPy支持比Python更多的数据类型。下面介绍一些常用的数据类型,以及这些数据类型之间的转换。通过“ndarray.dtype”可以创建一个表示数据类型的对象。要想获取数据类型的名称,则需要访问name属性进行获取,示例代码如下。查看全文>>














 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营














.jpg)